











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 大数据新闻动态 大数据技术文章 大数据常见问题 技术问答
-
-
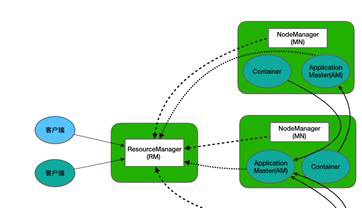
简单介绍YARN资源管理框架的体系结构【大数据文章】
YARN是一个通用的资源管理系统和调度平台,它的基本设计思想是将MRv1(Hadoop1.0中的MapReduce)中的JobTracker拆分为两个独立的任务,这两个任务分别是全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中,ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。接下来,我们通过一张图来描述YARN的体系结构,具体如图1所示。 查看全文>>
大数据技术文章2020-11-03 |传智播客 |YARN,YARN资源管理框架的体系结构
-
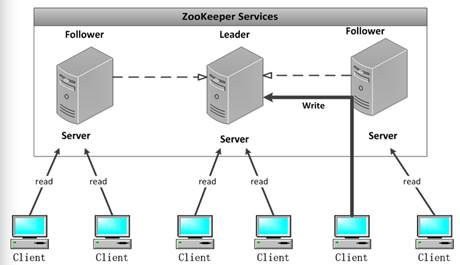
Zookeeper分布式系统的集群架构介绍
Zookeeper对外提供一个类似于文件系统的层次化的数据存储服务,为了保证整个Zookeeper集群的容错性和高性能,每一个Zookeeper集群都是由多台服务器节点(Server)组成,这些节点通过复制保证各个服务器节点之间的数据一致。只要当这些服务器节点过半数节点可用,那么整个Zookeeper集群就可用。下面我们来学习Zookeeper的集群架构,如图1所示。 查看全文>>
大数据技术文章2020-11-03 |传智播客 |Zookeeper分布式系统,Zookeeper集群角色
-
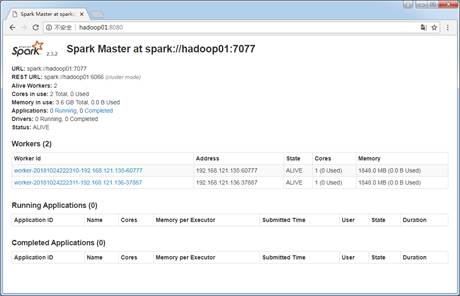
Spark的集群安装与配置简介【大数据技术文章】
要规划的Spark集群包含一台Master节点和两台Slave节点。其中,主机名hadoop01是Master节点,hadoop02和hadoop03是Slave节点。接下来,分步骤演示Spark集群的安装与配置,具体如下。 查看全文>>
大数据技术文章2020-10-29 |传智播客 |Spark的集群安装与配置简介
-

什么是Scala?Scala发展历程简介
Scala是Scalable Language的简称,它是一门多范式的编程语言,其设计初衷是实现可伸缩的语言、并集成面向对象编程和函数式编程的各种特性。 查看全文>>
大数据技术文章2020-10-28 |传智播客 |Scala发展历程简介
-
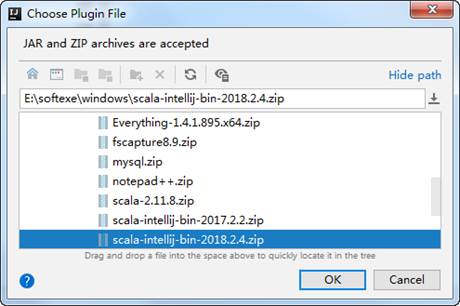
Windows系统中怎样下载安装Scala插件?
IDEA工具可以自动识别代码错误和进行简单的修复、以及IDEA工具内置了很多优秀的插件,所以现在大多数的Scala开发程序员都会选择IDEA作为开发Scala的工具。接下来,以Window操作系统为例,分步骤讲解如何在IDEA工具上下载安装Scala插件,具体步骤如下: 查看全文>>
大数据技术文章2020-10-28 |传智播客 |如何下载安装Scala插件
-

HBase分布式数据库有哪些特点?HBase简介
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式数据库,它起源于2006年Google发表的BigTable论文。在2008年,PowerSet的Chad Walters和Jim Keller受到了该论文思想的启发,从而把HBase作为Hadoop的子项目来进行开发维护,用于支持结构化的海量数据存储。 查看全文>>
大数据技术文章2020-10-28 |传智播客 |HBase分布式数据的特点
-
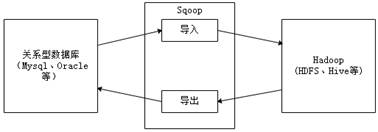
什么是Sqoop,Sqoop在开发中起到什么作用?
Sqoop是Apache旗下的一款开源工具,该项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,并在2013年,独立成为Apache的一个顶级开源项目。 查看全文>>
大数据技术文章2020-10-16 |传智播客 |Sqoop是什么
-
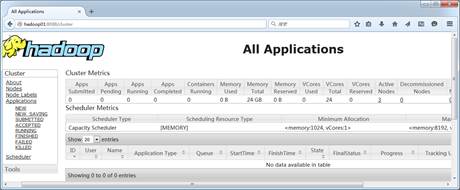
Hadoop集群怎么通过UI界面实现集群的管理
想要通过外部UI界面访问虚拟机服务,还需要对外开放配置Hadoop集群服务端口号。这里,为了后续学习方便,就直接将所有集群节点防火墙进行关闭即可,具体操作如下。 查看全文>>
大数据技术文章2020-10-16 |传智播客 |Hadoop集群集群的管理和查看
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
