











 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 大数据新闻动态 大数据技术文章 大数据常见问题 技术问答
-
-

Scala的控制结构语句有几种?各语句的语法格式是什么?
在Scala中,控制结构语句包括条件分支语句和循环语句。其中,条件分支语句有if语句、if...else语句、if...else if...else语句以及if...else嵌套语句;循环语句有for循环,while循环和do...while循环。条件分支语句和循环语句的语法格式具体如下。 查看全文>>
大数据技术文章2020-12-17 |传智教育 |控制结构语句的语法格式
-
IDEA工具开发WordCount单词计数程序的相关步骤有哪些?
Spark作业与MapReduce作业同样可以先在本地开发测试,本地执行模式与集群提交模式,代码的业务功能相同,因此本书大多数采用本地开发模式。下面讲解使用IDEA工具开发WordCount单词计数程序的相关步骤。 查看全文>>
大数据技术文章2020-12-17 |传智教育 |开发WordCount单词计数程序的相关步骤,Spark
-

Scala的声明值和变量【大数据文章】
Scala有两种类型的变量,一种是使用关键字var声明的变量,值是可变的;另一种是使用关键字val声明的变量,也叫常量,值是不可变的。这里需要说明的是,虽然声明值和变量的方式比较简单,但是有以下几个事项需要注意: 查看全文>>
大数据技术文章2020-12-17 |传智教育 |Scala声明值和变量
-
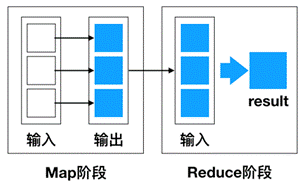
MapReduce编程的两种数据流模型演示
MapReduce是一种编程模型,用于处理大规模数据集的并行运算。使用MapReduce执行计算任务的时候,每个任务的执行过程都会被分为两个阶段,分别是Map和Reduce,其中Map阶段用于对原始数据进行处理,Reduce阶段用于对Map阶段的结果进行汇总,得到最终结果,这两个阶段的模型如图1所示。 查看全文>>
大数据技术文章2020-12-17 |传智教育 |MapReduce编程模型,大规模数据集的运算
-
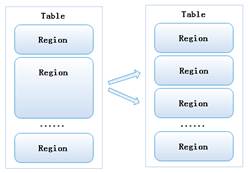
HBase数据库是怎样存储数据的?
HBase分布式数据库最重要的就是存储数据,下面,从四个方面详细介绍HBase的物理存储。 查看全文>>
大数据技术文章2020-12-17 |传智教育 |数据存储,HBase物理存储机制
-

HDFS分布式文件系统的优点缺点分别是什么?
随着互联网数据规模的不断增大,对文件存储系统提出了更高的要求,需要更大的容量、更好的性能以及安全性更高的文件存储系统,与传统分布式文件系统一样,HDFS分布式文件系统也是通过计算机网络与节点相连,但也有传统分布式文件系统的优点和缺点。 查看全文>>
大数据技术文章2020-12-16 |传智教育 |HDFS,HDFS分布式文件系统的优点
-

怎样使用Linux和HDFS创建RDD?
Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。这里以Linux本地系统和HDFS分布式文件系统为例,讲解如何创建RDD。 查看全文>>
大数据技术文章2020-12-07 |传智教育 |创建RDD,RDD
-

什么是Sqoop?Sqoop发展历程简介
Sqoop是Apache旗下的一款开源工具,该项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,并在2013年,独立成为Apache的一个顶级开源项目。 查看全文>>
大数据技术文章2020-12-07 |传智教育 |Sqoop,什么是sqoop
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
